
Object detection in drone-captured image using YOLO-v3
SNU Department of System Semiconductor Engineering for AI
Kyunghyun Ryu, Pureun Kim, Keemin Kim
2nd Prize
Contest Description
The contest aimed to develop an object detection code with given drone-captured images and labeled data. Participants were restricted to using only the given dataset to train the network and used identical servers for training. Moreover, they are allowed to use the server only for one week. The assessment criteria were mean Average Precision (mAP) of code.

Our work
Detector selection
Due to the limited time, we thought training the existing network would be reasonable. We chose YOLO-v3 for the object detector. It gives better mAP than other real-time detection systems, and its pre-trained weight works well with different test sets (more generalized). Our training used YOLOv3-416 pre-trained weight.
Parameter tuning
We modified several hyperparameters for effective training. Main reference for our parameter tuning is [1] Reference.
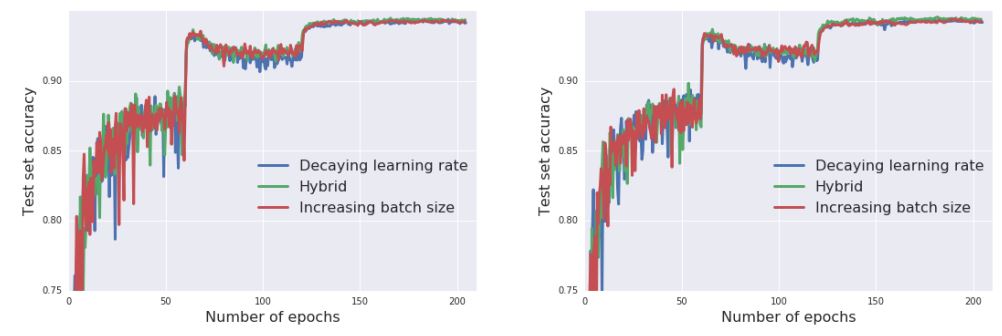
During the training, a large learning rate at the start of training could decrease loss very fast. However, a large learning rate prevents the network from converging to a local minimum and oscillates as training continues. On the contrary, learning rate decay accelerates learning in the initial phase and prevents oscillation in the final stage. According to [1], we can obtain the same learning curve with learning rate decay by increasing the batch size.
 [1]
[1]
Therefore, we modified the subdivision of YOLO to speed up the training process. Subdivision is how many mini-batches it splits its batch in. By reducing the subdivision rate, YOLO sends more images to GPU simultaneously (Increasing mini-batch size). It not only speeds up the training but also generalizes the training more.
However, usually batch size is limited to GPU memory. Therefore, we also used a step decaying learning rate with regard to the training epoch.
Data Augmentation
In the given dataset, some classes were suffered from the small number of images in those classes. We leveraged data augmentation for the classes with few training images. Data augmentation is increasing the number of training data with minor alterations. We used flip and rotation for several images in such classes.
Results

We successfully detected and classified objects in the images. Moreover, we ranked 2nd highest mean Average Precision (mAP) in the contest.
[1] Smith, Samuel L., et al. “Don’t decay the learning rate, increase the batch size.” arXiv preprint arXiv:1711.00489 (2017).